Reprise de données
La Reprise de données permet d’importer dans le logiciel des données présentes dans un fichier CSV ou Excel. (La reprise peut également se faire au format XML ou JSON grâce aux API)
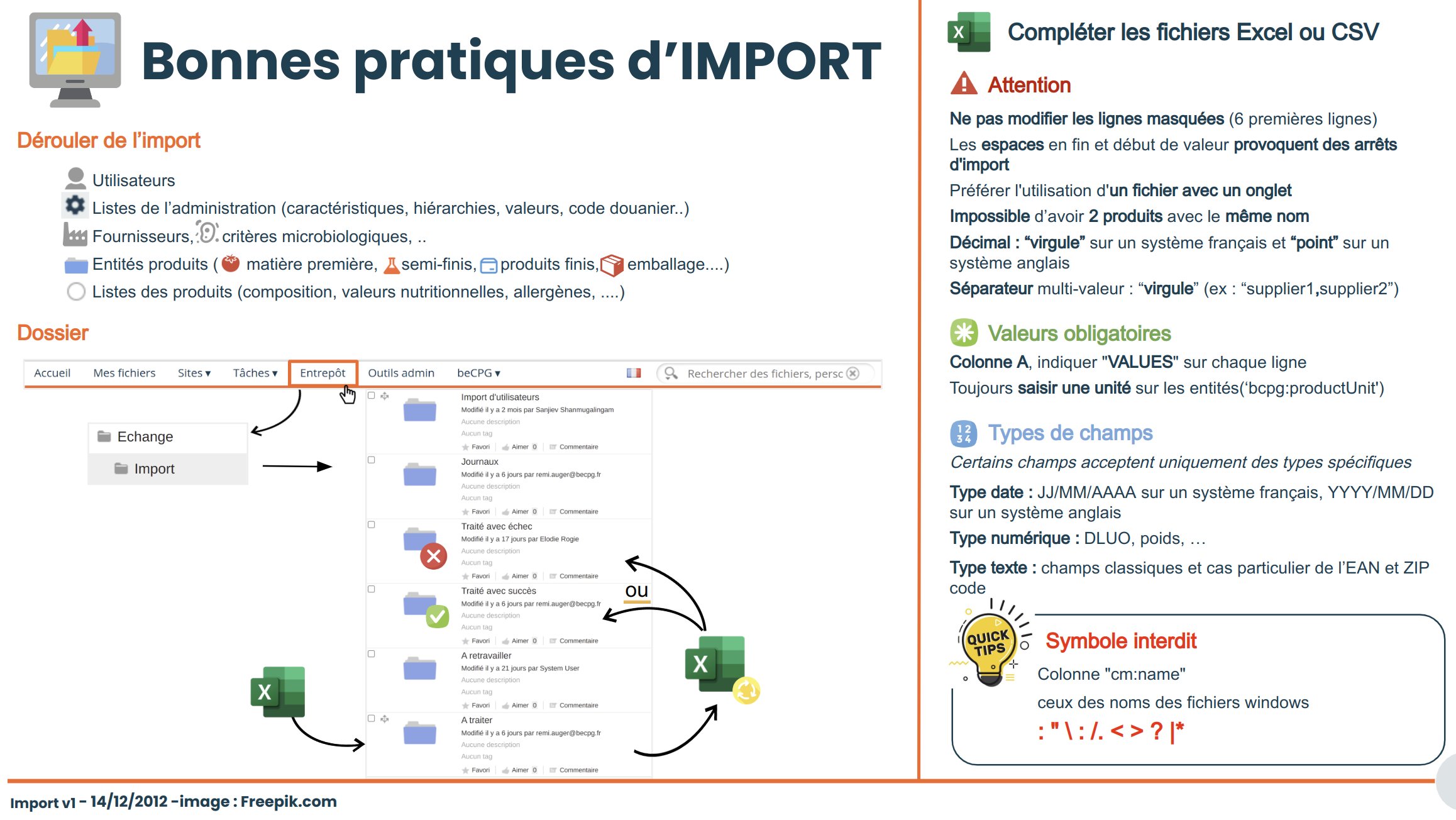
Utilisation
Les dossiers utilisés pour l'import se trouvent dans l'entrepôt (Entrepôt/Échange/Import):
Les dossiers utilisés pour l'import sont:
- A traiter : pour importer des fichiers CSV ou XLSX;
- Traité avec échec : fichiers en erreur;
- Traité avec succès : fichiers importés avec succès;
- Log : Log d'import;
- A retravailler : dossier de stockage;
- Import d'utilisateurs : permet d'importer des utilisateurs.
Il est possible d'obtenir les trames en utilisant directement les exports excel générés dans l'interface, dans les listes ou via l'édition multiple (cf. Outils).
beCPG fourni également des trames vierges au format Excel ou CSV pouvant être utilisées pour la reprise de données:
Pour télécharger les fichiers, faites un clic droit sur le lien ci-dessous.
Il est possible d'utiliser le format CSV en enregistrant le fichier excel au format CSV avec comme séparateur le point virgule (;)
Ci-dessous les points à respecter pour l'utilisation des trames
Le paramétrage des imports
Le format d'import est le suivant :
TYPE; bcpg:rawMaterial
PATH; /Exchange/Import/ImportToDo/rawMaterial
COLUMNS_PARAMS; @Key
COLUMNS; bcpg:erpCode; cm:name bcpg:legalName;
#; Code ERP; Nom Libellé légal;
VALUES; FR001; Orange; Orange;
VALUES; FR002; Pomme; Pomme;
VALUES; FR003; Eau Reseau; Eau;
Où :
- PATH: est le dossier où sera importées les données;
- TYPE: le type d'objet créé (matière première, nutriment, etc...);
- LIST_TYPE : l'ID de la liste dans beCPG (survey:surveyList@1)
- COLUMNS: sont les noms des attributs (propriétés et association) à importer;
VALUES: sont les valeurs à importer en respectant un certain format :
date : JJ/MM/AAAA sur un système français, YYYY/MM/DD sur un système anglais;
utilisateur : le compte de l'utilisateur;
- nombre décimal : le séparateur décimal est la virgule sur un systèm français et le point sur un système anglais;
COLUMNS_PARAMS: des annotations permettant de spécifier le type de colonnes et les éventuels clés
Les annotations possibles:
Toutes les annotations respectent la règle de nommage suivante: @Nom(attribute1="", attribute2="", attribute3="",...etc)
- L'annotation commence par un @ suivie par le nom
- Le nom de l'annotation commence par une majuscule
- Les annotations possèdent des attributs
- Les noms des attributs commencent par une minuscule
- Les attributs sont séparés par une virgule
- Les annotations possèdent des attributs obligatoires et des attributs optionnels
Exemple
@Key: choisir l'identifiant de l'entité.
@Assoc: identifier l'association.
key: la clé de l'association. (obligatoire) path: pour spécifier le chemin de recherche. (optionnel) type: pour préciser le type de la cible. (optionnel)
@DataListKey: la clé utilisée dans une liste. (composition, emballage, ..etc).
@Hierarchy: la famille/sous famille.
path: le chemin de la liste des familles dans l'administration. (optionnel dans le cas des familles de produits) parentLevelColumn: la colonne parent c'est-à- dire la colonne famille. (obligatoire seulement pour les sous-familles) parentLevelAttribute: l'attribut qui relie la famille et la sous-famille, généralement c'est **bcpg:parentLevel**. (obligatoire seulement pour les sous-familles)
- @File: importer de fichier/image ..etc.
attribute: nom de la propriété utilisée, "cm:content", "cm:title", ...etc. (obligatoire) path: le chemin de destination. (obligatoire)
- @Attribute: importer un attribut depuis des propriétés de type d:nodeRef ou association.
attribute: le nom de la propriété. (optionnel) type: le type de la cible. (obligatoire) key: la clé de l'association. (cm:name si non renseigné)
- @Charact: importer les caractéristiques en colonne.
dataListQName: le nom de la liste de caractéristique. (Coûts, Nutriments, Allergènes, etc...). (obligatoire) charactQName: la propriété de la liste où est stockée la caractéristique. (obligatoire) charactKeyQName: la clé de recherche de l'association. (obligatoire) charactNodeRef: l'id de la caractéristique. (optionnel, si vide le système prends charactKeyValue ou charactName). (optionnel) charactKeyValue/charactName: le nom de la caractéristique importée. (optionnel, si vide le système prends le titre de colonne) charactKeyQName: le nom de la propriété utilisée pour chercher la caractéristique. (optionnel, si vide le système prends bcpg:charactName) dataListAttribute: l'attribut à remplir par la valeur de la colonne. (obligatoire)
@Formula: utiliser une formule SPEL dans une colonne.
@MLText: importer les champs multilangues sans ajouter le champ par défaut (qui n'a pas d'extension de langue comme "_en" ou "_fr", par exemple "bcpg:legalName")
S'il y a un champ par défaut mais qu'on utilise tout de même la propriété MLText, il faut l'ajouter sur la première colonne.Nb.
Le nom des annotations sensibles à la casse, il faut respecter les noms et les attributs obligatoires
On utilise une seule annotation par cellule ou vide si la colonne une propriété simple
Une colonne peut être une clé/assoc/MLtext en même temps, dans ce cas vous devez utiliser plusieurs lignes COLUMNS_PARAMS
Exemple:
Divers
Pour l'annotation @File correspondand au chemin vers les fichiers à importer il est possible d'utiliser les préfixes suivants :
- file: - Pour le chemin d'un fichier en local
- classpath:
- url:
- http: - Pour un fichier se trouvant sur un site web
- ftp: - Pour un fichier obtenu avec le protocole FTP
reg: - Accompagné de l'entête DOCS_BASE_PATH :
DOCS_BASE_PATH
Permet d'indiquer dans quel dossier se situent les documents à importer lors de l'utilisation de reg:
Nb. L'extension du fichier est conservée lors de l'import
IMPORT_TYPE
Permet d'indiquer le type d'import à réaliser :
- Node ou absence de ligne IMPORT_TYPE : on importe un objet (ex : MP, SF, PF, emballages,...)
- EntityListItem : on importe une liste associée à une entité (ex : compoList, ingList,...)
- Comments : on importe un commentaire
En cas d'erreur dans la saisie d'une datalist, il est possible de la ré-importer. Il faut supprimer l'ancienne datalist au moment du nouvel import en ajoutant le paramètre suivant :
DELETE_DATALIST true
- Cette fonction est équivalent à un "ANNULE ET REMPLACE"
STOP_ON_FIRST_ERROR false
- Permet de continuer l'import en cas d'erreur d'une ligne
DISABLED_POLICIES cm:auditable,rep:reportEntityAspect
- Désactive les polices lors de l'import (Génération du code beCPG par exemple ou alors contraintes non respectés)
ENTITY_TYPE
- Permet de spécifier le type d'entité lors de l'import par défaut c'est le type bcpg:product qui est utilisé.
Import d'utilisateurs
beCPG permet d'importer un lot d'utilisateurs et de les associer à des groupes et ou à des sites. Les sites et groupes non existants sont créés par l'import. L'import se fait par un fichier au format CSV qui doit être placé dans le dossier de l'entrepôt « Échange/Import/Import d'utilisateurs ». Une fois l'import exécuté, le fichier est automatiquement déplacé dans « Échange/Import/Traité avec succès ».
Le fichier CSV doit comporter une ligne en entête :
"cm:lastName";"cm:firstName";"cm:email";"cm:telephone";"cm:organization";"username";"password";"memberships";"groups";"notify"
Il est possible d'ajouter d'autres propriétés à l'utilisateur en rajoutant en entête le nom de la propriété. Les champs « username » et « password » sont obligatoires.
Le champ « membership » permet d'associer l'utilisateur à des sites en définissant son rôle au sein du site. Les différents rôles sont :
- Consumer
- Collaborator
- Manager
Les sites doivent être séparés par des « | » et le rôle avec « _ ». Ainsi l'utilisateur «Test » appartenant au site « Site de test 1 » avec le rôle Manager et « Site de test 2 » avec le rôle « Consumer » aura le champ « membership » rempli comme suit : « Site de test1_Manager|Site de test2_Consumer »
Le champ « groups » permet d'associer l'utilisateur à un ou des groupes. Les différents groupes sont séparés par « | » un groupe peut être hiérarchique il est représenté en utilisant le séparateur de chemin « / ». Les groupes beCPG doivent être référencés par leurs noms systèmes :
- Marketing (Marketing)
- Responsables marketing (MarketingMgr)
- Utilisateurs marketing (MarketingUser)
- Achats (Purchasing)
- Responsables Achats (PurchasingMgr)
- Utilisateurs Achats (PurchasingUser)
- Responsables Qualité (QualityMgr)
- Utilisateurs Qualité (QualityUser)
- R&D (RD)
- Responsables R&D (RDMgr)
- Utilisateurs R&D (RDUser)
- Réviseurs Produit (ProductReviewer)
- Responsables Système (SystemMgr)
Ainsi l'utilisateur appartenant au groupe « Réviseurs Produit » et au groupe « Groupe de test 2 » enfant de « Groupe de test 1 » aura le champ « groups » rempli comme suit : « ProductReviewer|Groupe de test 1/Groupe de test 2 »
Le champ « notify » permet d'envoyer un mail à l'utilisateur. Les valeurs possibles sont « true » ou « false ».
Un exemple complet de CSV pour l'utilisateur Test :
"cm:lastName";"cm:firstName";"cm:email";"cm:organization";"username";"password";"memberships";"groups";"notify"
"test";"test";"test@becpg.fr";"";"test";"test"; "Site de test 1_Manager|Site de test2_Consumer";"ProductReviewer|Groupe de test 1/ Groupe de test 2";"false"