Reports and product sheets
Introduction
This document introduces the configuration and administration of BIRT reports for beCPG. It is dedicated to be read by beCPG administrators. The following video introduces the modification of a BIRT report:
Prerequisites:
- Eclipse Birt,
- The eclipse plugin RessourceBundle,
- Basic knowledge of:
- XML
- XPATH (optional),
- Javascript
- Admin access to PLM.
BIRT Product Sheet Report
beCPG uses BIRT (Business Intelligence and Reporting Tools) software to generate data sheets. BIRT is an Open Source project that provides reporting and document generation tools. This tool is widely recognized for its flexibility and ability to produce data-rich and customized reports.
BIRT is an Open Source project supported by the Eclipse Foundation. The complete BIRT documentation is available at: BIRT Documentation. This documentation provides a comprehensive overview of the tool, including basic concepts, advanced features, and best practices for creating reports.
Installation
The different versions of BIRT can be found on this page: http://download.eclipse.org/birt/downloads/.
Depending on the version of beCPG, it is necessary to use the correct version of the BIRT editor. The table below shows these different versions:
| beCPG Report Version | Birt Version | Java Version | Eclipse RCP Birt Version |
|---|---|---|---|
| 4.20.0 | 4.20 | JDK 17 | BIRT RCP 4.20 |
| 4.17.0 | 4.17 | JDK 17 | BIRT RCP 4.17 |
| 4.15.0 | 4.15 | JDK 17 | BIRT RCP 4.15 |
| 3.2 | 4.8 | JDK 11 | Eclipse Photon |
Types of report
Product reports
There are 2 types of reports for the « Product »:
- system report (always automatically generated by the system);
- user report (chosen by the user when he edits the product). This kind of report is an upon request report.
These reports are defined in the folder : /System/Reports/Product reports
To add a new report:(note: you can copy and paste a product report)
1.Add a folder;
2.Add the file: .rptdesign and edit its metadata :
- the name of the report;
- The type of product for which the report will be a applied; Raw material by adding: {http://www.bcpg.fr/model/becpg/1.0}rawMaterial
Semi-finished product by adding: {http://www.bcpg.fr/model/becpg/1.0}semiFinishedProduct
Finished product by adding : {http://www.bcpg.fr/model/becpg/1.0}finishedProduct
Packaging by adding : {http://www.bcpg.fr/model/becpg/1.0}packagingMaterial
It's also possible to enter a general type. A general type allows the report to be visible by all entities. General Type : {http://www.bcpg.fr/model/becpg/1.0}product
- The model type : System model to indicate if the report is automatically generated for this type of product. In the case where the report isn’t a system report, the user should select it when he edits the product.
Default model to specify that the report is the one per default on the product which means that it will be displayed by default when the button « Create the report » is pressed.
- There can be only one default report per product type. Reports which are not default reports are put by default to the « Documents » folder of the product when the report is being generated.
- The report extension
When a product is created or edited, the system generates one report per report model associated to the product.
Search exports: EXCEL
Excel search exports are easy to create.
An Excel file corresponds to a single type of entity (finished product, MP, ...)
It includes several tabs. Each tab corresponds to a list of the entity (property, ingredients, composition, ....). The first tab always corresponds to the property list of the entity. It is at the level of this first tab that you must define the type of entities on which your search relates.
It is up to you to define: which entity, which lists and which fields interest you.
To be able to create your file, you will need to know the names of the internal beCPG fields (see How to find the internal beCPG fields?
First tab
Define the type of entities:
Whatever the tab, there will always be information in box A1 of your EXCEL file.
Under the 1st tab:
- A1: TYPE
- A2: the type of entity on which your search relates (bcpg:finishedProduct, bcpg:rawMaterial, ...)
| KIND | bcpg:finishedProduct | ||||
|---|---|---|---|---|---|
| COLUMNS | cm:name | bcpg:code | bcpg:erpCode | bcpg:productHierarchy1 | bcpg:productHierarchy2 |
| # | Name Code | Code Becpg | Code ERP | Family | Subfamily |
Other tabs
On the following tabs you can extract the datalists of the entity or the content of the different lists.
- A1: TYPE
- A2: The list to which your extraction relates
Example the "Composition" list
| KIND | bcpg:compoList | ||
|---|---|---|---|
| COLUMNS | bcpg:erpCode | bcpg:compoListProduct | bcpg:compoListProduct_bcpg:productHierarchy1 |
| # | Erp code | Recipe component | Component family |
Specificities
You can use the entity_ prefix to display entity properties in datalist type tabs.
- Export of datalists in column
Since version 2.5, it is also possible to display the datalists of an entity in a column, i.e. you will no longer need to create several tabs to have the elements of a datalist linked to a product. With this new export, you will have the fields of your entity followed by the elements of the datalist on the same line.
Formula to use:
name_of_the_datalist [ name_of_the_association # search_item == " search_value " ]_ field_to_display
Example:
Export of the fortuitous presence of the "Soybean and soybean-based products" allergen of finished products
bcpg:allergenList[bcpg:allergenListAllergen#bcpg:allergenCode == "FX5"]_bcpg:allergenListInVoluntary
| KIND | bcpg:finishedProduct | ||||
|---|---|---|---|---|---|
| COLUMNS | cm:name | bcpg:code | bcpg:erpCode | bcpg:allergenList[bcpg:allergenListAllergen#bcpg:allergenCode == "FX5"]_bcpg:allergenListInVoluntary | |
| # | Name | Code Becpg | Code ERP | Accidental presence of soy and soy-based products |
- The dynamic characteristics:
In the composition, packaging or process lists, it is possible to have dynamic characteristics. If you want the list of dynamic characteristics, by entity:
| KIND | bcpg:dynamicCharactList | ||||
|---|---|---|---|---|---|
| COLUMNS | bcpg:code | bcpg:dynamicCharactTitle | bcpg:productHierarchy1 | bcpg:productHierarchy2 | |
| # | Code Becpg | Dynamic characteristics |
If you retrieve the value of a specific dynamic characteristic from the composition list, for example, your column header will be constructed as follows: dyn_property_name
Example :
| KIND | bcpg:compoList | ||
|---|---|---|---|
| COLUMNS | bcpg:erpCode | bcpg:compoListProduct | dyn_nom_de_la_charact_dynamique |
| # | Erp code | Recipe component | dynamic character name |
- Multilevels and Formulas
For bcpg:compoList and bcpg:packagingList types you can use multilevel extraction parameters (AllLevel, MaxLevel2, OnlyLevel2) as well as formulas whose column headers will be constructed as follows: formula|props["formula name"] (example by indicating in the column header: formula|props["qty"])
| TYPE | bcpg:compoList | OnlyLevel2 | |
|---|---|---|---|
| COLUMNS | bcpg:erpCode | bcpg:compoListProduct | bcpg:compoListProduct_bcpg:erpCode |
| # | Erp code of entity | Product Component | ERP code of component |
- Allocation :
The allocation plugin allows to extract information about materials used in collections or products. To use it, it is necessary to specify the "Allocation" parameter on the bcpg:compoList type. The available fields are:
- "Quantity" (kg): formula|props["qty"]
- "Quantity per product" (%): formula|props["qtyForProduct"]
- Entity fields: entity|
- Product fields: product|
Here is an example data structure to use this plugin:
|TYPE |bcpg:compoList|Allocation|
| COLUMNS | bcpg:erpCode | cm:name | formula|props["qty"] | formula|props["qtyForProduct"] | entity|cm:name | entity|bcpg:productCollectionHierarchy1 | product|cm:name | product|bcpg:productHierarchy1|
| # | ERP code | Material | Qty | Qty per product | collection | Collection Family | Product | Product family|
Spreadsheet function
Use the results of your searches by integrating an additional tab with EXCEL formulas (searchV, searchH, ....) To identify the tab that uses the spreadsheet function of EXCEL, the first box (A1) must contain the symbol #.
You can also define a column by inserting an EXCEL formula directly or a text like:
excel|SUM(A1:A10)
Image Export
Several formulas can be used to download images stored on entities in beCPG :
- URL finder:
formula|@img.getEntityImagePublicUrl()
formula|@img.getEntityImagePublicUrl($nodeRef)
formula|@img.getImagePublicUrlByPath($nodeRef, "./cm:Images/cm:produit.jpg")
formula|@img.getImagePublicUrlByPath($nodeRef, "./cm:Dossier/"+dataListItem.name+".jpg")
Once you have the public URL of the image in the specific column, you can use it in a second column by using the Excel function =IMAGE to insert the image into Excel.
excel|IMAGE(H2)
- Get the image directly from the export :
image|@img.getEntityImageBytes()
image|@img.getEntityImageBytes($nodeRef)
image|@img.getImageBytesByPath($nodeRef, "./cm:Images/cm:produit.jpg")
image|@img.getImageBytesByPath($nodeRef, "./cm:Dossier/"+dataListItem.name+".jpg")
$nodeRef corresponds to a SPEL formula that allows you to retrieve the product or image node.
ex:
formula|@img.getEntityImagePublicUrl(entity) or for list formula|@img.getEntityImagePublicUrl(datalistItem)
Search exports: BIRT
Only for reports: BIRT
- The definition of the data to be exported for the report is defined
in ExportSearchQuery.xml. This file defines the attributes of the
product to export for running the report:
- product properties (name, state, etc...);
- product associations (suppliers, customers, etc.);
- product characteristics (costs, nutrients, allergens, etc...).
To create or modify a BIRT report, refer to the chapter “Modifying a produced report template”.
Installing search exports
These reports are defined in the folder: /System/Reports/Research Exports
These reports are BIRT reports that export the result of a research.
Adding a new report is done as follows:
- Add folder;
- In the file, add the BIRT or EXCEL report by filling in the name and its metadata. The name will be displayed on the results page of an advanced search. The file extension must be xls for a EXCEL report and rptdesign for a BIRT report.
- Set permissions on the report folder. The people must have read permission to view the report in the search result.
Here is the list of some metadata to configure:

- The export Name, as generated by the system.
- The export Type: keep "ExportSearch" in this case.
- The "Class name**: allow to filter on entities to consider for the export. To filter on FP:
{http://www.bcpg.fr/model/becpg/1.0}finishedProduct
To filter on SFP:
{http://www.bcpg.fr/model/becpg/1.0}semiFinishedProduct
To filter on RM:
{http://www.bcpg.fr/model/becpg/1.0}rawMaterial
To filter on Packaging:
{http://www.bcpg.fr/model/becpg/1.0}packagingMaterial
To filter on Kit :
{http://www.bcpg.fr/model/becpg/1.0}packagingKit
To filter on all product types (FP, SFP, RM, Packaging, Kit) :
{http://www.bcpg.fr/model/becpg/1.0}product
Search limit : allow you to choose the maximum number of lines extracted in the export. By default, it's 1000.
Is disabled : desactivate the export without deleting it.
Search exports: ZIP
Exports de recherche ZIP
Documents from entities can be exported to a ZIP file. To do this, simply create an XML file in Repository > System > Reports > Search exports > Product exports.
This file must contain the export settings with one line for each condition.
<file/>
It is possible to filter the extracted entities, select the documents to be exported, define the names of the files after extraction, and the name of the folder in which they will be organized.
Export by inclusion:
example : documents whose name contains the word ‘xxx’
<export format="zip">
<file entityFilter="spel(hierarchy1.toString().equals('[family node CHEESE]'))" path="cm:Documents/*[like(@cm:name, '%recette%', false)]" name="{doc_cm:name}" destFolder="CHEESE"/>
</export>
In this example:
- 'entityFilter': filter on entities that have the ‘Cheese’ family
- 'path': filter on documents that have the word ‘recipe’ in their name
- 'name': renames the document by itself
- 'destFolder': stores the document in the ‘Cheese’ folder during extraction
Export by exclusion:
example : documents whose name does not contain the word ‘xxx’
<export format="zip">
<file entityFilter="spel(@beCPG.assocPropValues(nodeRef,'bcpg:trademarkRef','cm:name')[0]=='Brand X')" path="*/*[like(@cm:name, '%png', false) and not (like(@cm:name,'xxx')) and not (like(@cm:name,'zzz')) ]" name="{bcpg:eanCode} {bcpg:productVersion} {doc_cm:name}" destFolder="png/Brand X"/>
</export>
In this example:
- 'entityFilter': filters entities that have the 'Brand X' tag
- 'path': filters documents that have the 'png' extension but do not have the words 'xxx' and 'zzz' in their name
- 'name': renames the document with the EAN code and entity version, followed by the document name
- 'destFolder': saves the document in the 'png' folder, then the 'Brand X' subfolder
Export allowing filtering based on entity association
<export format="zip">
<file entityFilter="js(entity.assocs['bcpg:productGeoOrigin'] && entity.assocs['bcpg:productGeoOrigin'].length > 0 && entity.assocs['bcpg:productGeoOrigin'][0].properties['bcpg:charactName'] == 'Africa')" path="*/*[like(@cm:name, '%pdf', false)]" name="{doc_cm:name}" destFolder="A3P"/>
</export>
In this example:
- 'entityFilter': JavaScript formula that filters entities with the geographical origin association 'Africa'
- 'path': filters documents with the extension 'pdf' but without the words 'xxx' and 'zzz' in their name
- 'name': renames the document itself
- 'destFolder': stores the document in the 'A3P' folder
How to find the name of the fields in beCPG
The name of the fields can be found in the properties list of a product and in the lists (composition, packaging...)
To find the name of the fields which are present in "Properties", you must edit the properties, right click and inspect the element.
To find the name of the lists:
- You can either extract the list by clicking on the Excel logo
- Or use the node browser (see http://docs.becpg.fr/en/development/Import.html)
Other sheets On the other sheets, data lists can be extracted from the principal type. Example for the composition :
| TYPE | bcpg:compoList | ||
|---|---|---|---|
| COLUMNS | bcpg:erpCode | bcpg:compoListProduct | bcpg:compoListProduct_bcpg:productHierarchy1 |
| # | ERP Code | Recipe component | family of the component |
Columns and types of attributes are internal names given to fields.
Since version 2.5, it is also possible to display the datalists of an entity in column. Thus, you will not need to create a tab for each datalist linked to a product. With this new export, you will have the fields of your entity followed by the datalist's elements on the same line.
Formula to use :
datalist_name [ association_name # search_element == " search_value " ]_ field_to_display
Example:
Export of the cross contamination by the allergen "Soybeans and soy products" of finished products
bcpg:allergenList[bcpg:allergenListAllergen#bcpg:allergenCode == FX5"]_bcpg:allergenListInVoluntary
| TYPE | bcpg:finishedProduct | ||||
|---|---|---|---|---|---|
| COLUMNS | cm:name | bcpg:code | bcpg:erpCode | bcpg:allergenList[bcpg:allergenListAllergen#bcpg:allergenCode == "FX5"]_bcpg:allergenListInVoluntary | |
| # | Name | Code | ERP Code | Cross contamination by soybeans and soy products |
Modification of a product report model
Each beCPG report has a BIRT model for which the extension is .rptdesign. h3. BIRT introduction
beCPG is based on a reporting solution : BIRT (Business Intelligence and Reporting Tools).
- Reporting: synthesizes data in the forms of reports.
- BIRT:
- reporting tool "Open Source" based on Eclipse.
- graphical tool, which means that it disposes a palette allowing the selection of the element which should be placed on the report.
The BIRT report can be connected with a database in order to display the result of a SQL query on the worksheet. For this purpose, it’s necessary to add a « Data source » allowing the connection to the data base.
Then the addition of a « Data set », containing the SQL query, allows the generation of static queries but also dynamic queries by adding editable parameters when the report is being generated.
The « Data cube » allows the creation of a « crossed table ». This allows notably to display data in the form of columns and the automatic computation of the total for statistics.
The beCPG report execution is done like this :
- Generation of the XML data source by the beCPG motor ;
- BIRT model load ;
- Execution of the report which will give an exit .pdf,.doc,.xls
Report design
The report design is done in the Eclipse designer where are found :
- The tool box (palet) which gives access to render controls such as: tables, lists, text areas …
- XML data source (Data Explorer);
- The formatting of the report (Layout);
- The masterpage : to modify the page header and/or footer ;
- The report preview.
The report configuration consists in :
- arranging tables, text areas …
- defining where will be placed the data, through drag and drop of datasource attributes, in the report.
Report creation
- Window > Open perspective > Other > Report Design
- File> New> Project> Business Intelligence and Reporting Tools> Report project. Then, name the project.
- File> New> Report. Then, name the report and choose the starting weft.
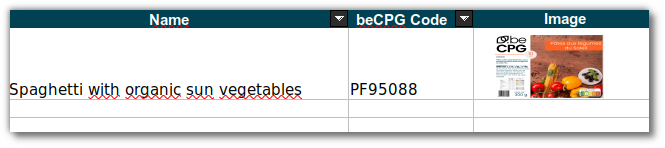
Data explorer
Select the « Data explorer » tab in order to explore the data.
An example of XML data source is :
<code class="xml">
<entity name="8 sushis assortment" code="1009"
store-identifier="SpacesStore"
productQty="0.200" productUnit="kg" productState="ToValidate"
productEAN="8001456682" />
</code>
This XML can be obtained thanks to the URL :
http://{serveur}:8080/alfresco/service/becpg/report/datasource?nodeRef=workspace://SpacesStore/2aad6284-afc2-4d89-8bbf-bd3dd50ff1bc
OR
http://{serveur}:8080/share/proxy/alfresco/becpg/report/datasource?nodeRef=workspace://SpacesStore/2aad6284-afc2-4d89-8bbf-bd3dd50ff1bc
Where « workspace://SpacesStore/2aad6284-afc2-4d89-8bbf-bd3dd50ff1bc » corresponds to the product identifier (available in the URL of the navigator when we are in a product). This URL displays the XML which can be saved on the PC by pressing « Save as ».
XML indentation :
xmllint --format datasource.xml > datasource-pretty-print.xml
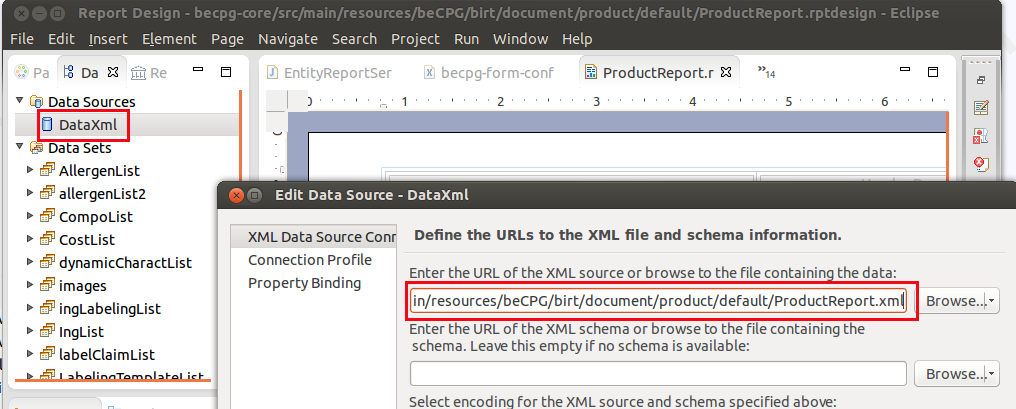
Data source choice
To modify a datasource, here is the procedure to be followed :
- Data explorer> Data source> New data source;
- Select « XML Data Source » ;
- Right click, « Edit »;
- Press « Browse » to search the data source;
- Select the XML saved on the computer;
- Press « Test connection » and write the ID and the password of the administrator ;
- If « Ping succeedeed » appears, it’s OK.
- Press « Finish ».
XML choice :
Data Sets
Data sets allow the examination of the data source and the selection of attributes.
- Data set> New data set. Then, click on the data source previously entered and press « OK ».
- Select the data to be examined (Xpath which allows the selection of XML nodes which feed the dataset) ;
- Select XML nodes’ attributes which feed the dataset columns.
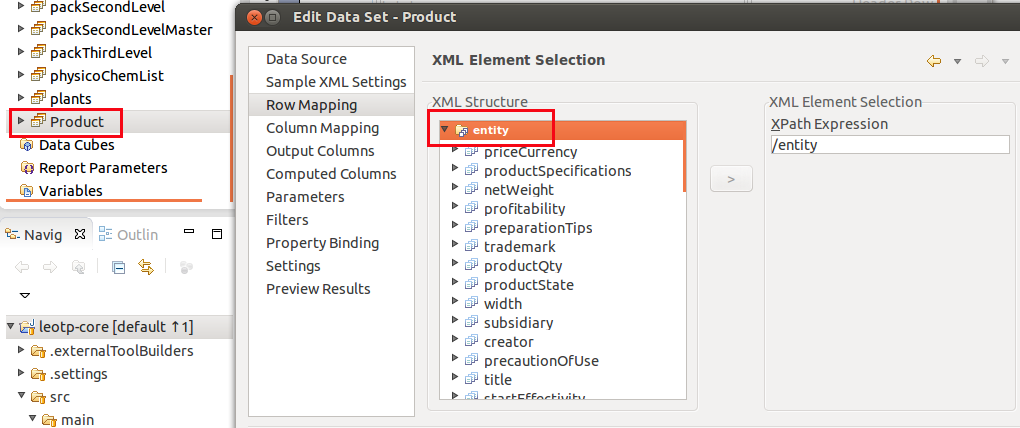
Addition of a property :
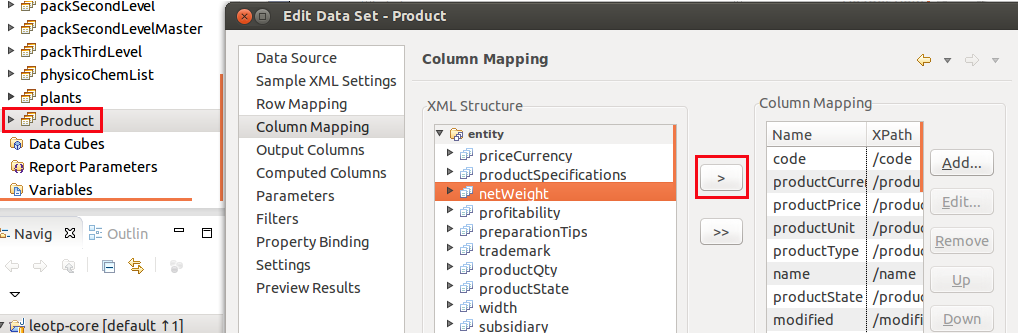
It’s possible to preview the content of a dataset by clicking on « Preview results ». Once the dataset has been parameterized, its data have to be dragged and dropped in the report.
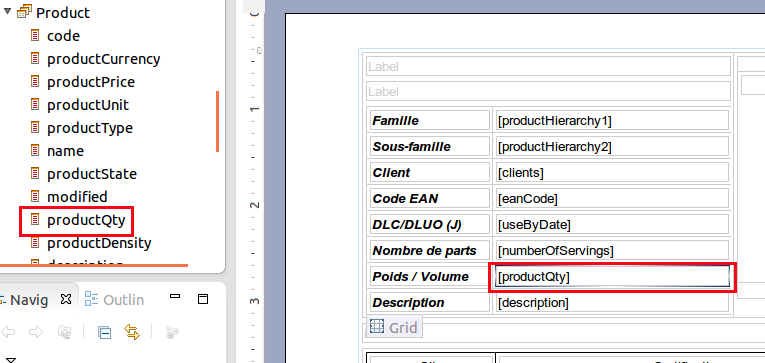
Report visualization
In order to select different report views, click on the different tabs below the principal section.

Layout
The layout allows the construction of the report :
- Controls addition ;
- Data addition.
Master page
The master page allows to complete:
- The report header and footer ;
- The report width and height.
Script
It’s possible to program usable functions in the report by storing them in the « Script » tab. These scripts can be executed at the starting or at the closing of the report, for a precise element or for the report in its integrality. The XML source code is accessible.
XML Source
Displays the report XML.
Preview
Displays the report preview, as if it was executed per beCPG : Run> View report> Exit format (PDF).
Controls palette
The palette is selected through the « Palette » tab. It allows to add static text.
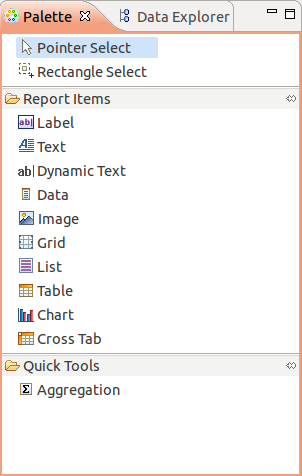
Available controls
- Label : to add static text ;
- Text ;
- Dynamic Text: dynamic text. Example : to put words in bold on the label, HTML beacons are used ;
- Data : rarely necessary because data are added from « Data explorer » ;
- Image ;
- Grid : static grid (tables can be added inside);
- List : dynamic list according to the number of lines in the dataset ;
- Table : dynamic table according to the number of lines of the dataset (lists can be put inside) ;
- Chart ;
- Cross table.
Control addition in a report
The addition of a control is done by drag and drop.
Images addition
The addition of a static image is simple.
The addition of a dynamic image is more complexe. In that case, the beCPG motor gets an image associated to a product and sends it to the data source of the report during its execution. The procedure is as follow :
- Add the image ;
- Dynamic image by referencing the image ID given to the datasource, example :row["productImage"]
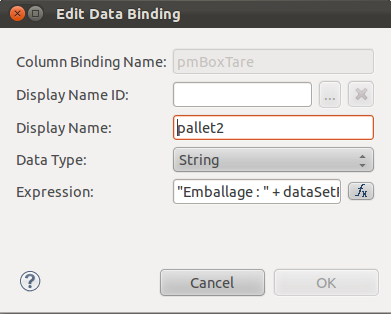
Data type fields expression
Data type fields can undergo conditions or be the concatenation of many attributes, example :
"Packaging : " + dataSetRow["palletBoxName"] + ", indicative tare (g) : " + dataSetRow["pmBoxTare"] + ", dimensions (mm) : " + dataSetRow["pmBoxDimensions"]
To edit this formatting : :
- Click right on the data attribute ;
- Edit Value/Expression ;
- Fill the expression.
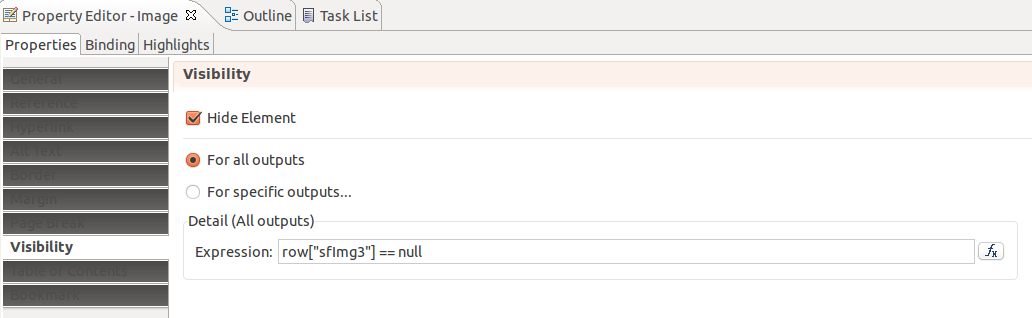
Visibility
It’s possible to hide fields or images according to certain conditions . For this purpose :
- Display the control properties ;
- Select the « Visibility » tab ;
- Fill the expression which indicates when hiding the control.
Formatting
It’s possible to define formatting styles in a report. For this purpose :
- Click right on a control ;
- Style : new style.
Then, styles can be applied to controls, edited or deleted : right click on a control and press « Style ».
Deployment
Once the report has been edited under Eclipse, save it in the format .rptdesign.
- Technical sheets ? Repository> System> Reports> Product reports> Entity and drop the report ;
- Languages files (properties) ? Repository> System> Reports> Product reports and drop the report.
In « Edit the properties », choose :
- System model if the report has to be attributed to all the products of the same type ;
- Default model if there exists many models and that this latter has to be displayed per default ;
- If nothing is ticked, go to the concerned product and select the report by hand.
To translate the report in different languages, associate language files to it. Select different languages in the drop down list too.
JXLS report
JXLS report presentation
JXLS format is useful for generating reports direcly from an XLSX editor like Excel. This file is based on the use of SpEL formulas for the data extraction.
This feature has been added to beCPG 3.2.1 - 2020/02/13
To read more about JXLS: http://jxls.sourceforge.net/
Setting
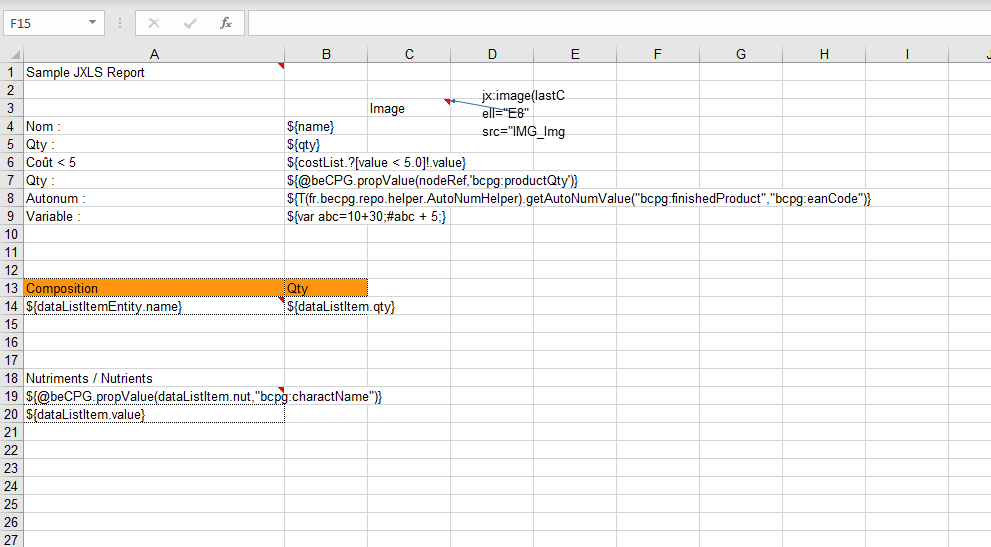
Here is an example of JXLS file:
Notes
Notes (or comments) are key for these files. You have to use them in 3 situations:
- File and formulas data range
This note is mandatory and is put usually in the A1 cell. In our example, formulas are working from the cell A1 to E20:
jx:area(lastCell="E20")
- Datalists
For datalists, the note must be in the first column cell. In our example, for the composition datalist, the note is set in the A14 cell. This note is used to define the datalist which must be exported and the range that must be considered. In our case, the range is between A14 to B14:
jx:each(items="compoListView.compoList" var="dataListItem" lastCell="B14")
Item values depend on the datalist you want to extract. If you want to extract the packaging list, then use:
jx:each(items="packagingListView.packagingList" var="dataListItem" lastCell="B14")
var value is ALWAYS "dataListItem".
It's also possible to export columns. You can add direction="RIGHT", as in the Nutrients export of our example:
jx:each(items="nutList" var="dataListItem" lastCell="A20" direction="RIGHT")
It's also important to notice that when datalists are imported, table dimensions are automatically adjusted. If a datalist has 3 values, then the export will consider 3 lines and shift 3 lines below. So, there is no risk of overlap.
- Pictures
The note is used to define picture dimensions (in cells) and to call the picture to export:
jx:image(lastCell="E8" src="IMG_Img0" imageType="PNG")
The image name in src is ALWAYS preceeded by "IMG_".
Fields export
Fields export are done with SpEL formula, between:
${...}
For example, if you want to extract the beCPG code:
${@beCPG.propValue(nodeRef,'bcpg:code')}
For more informatin on SpEL formulas, please read:
https://docs.becpg.fr/en/development/spel_formulas.html
Release
Once the XLSX file is ready, it's time for release. To do so, you should follow the same procedure as for BIRT report release. You only have to choose "XLSX as report format, and rename the ".xlsx" in ".jxls".
WARNING: everytime you update a new version over your jxls report, the format will be reintialised in ".xlsx". You have to change it again to ".jslx".
Extractor
Extractor Configuration
The extraction parameters allow customization of data extraction.
| Global Parameter | Relative Parameter | Description |
|---|---|---|
| beCPG.product.report.componentDatalistsToExtract | componentDatalistsToExtract | Specifies lists to extract when the composition is extracted in multi-level or in associations extracted with a list, or in the raw material list. The second argument specifies on which type of object to extract the list. |
| beCPG.product.report.assocsToExtract | assocsToExtract | Extracts association data. |
| beCPG.product.report.assocsToExtractWithImage | assocsToExtractWithImage | Extracts images from the association. |
| beCPG.product.report.assocsToExtractWithDataList | assocsToExtractWithDataList | Extracts lists from the association. |
| beCPG.product.report.assocsToExtractInDataList | assocsToExtractInDataList | Extracts association data in a list. |
| beCPG.product.report.entityDatalistsToExtract | entityDatalistsToExtract | Specifies lists to extract on the entity. |
| beCPG.product.report.multilineProperties | multilineProperties | Allows the property to be extracted in a CDATA field to retain line breaks. Instructions, descriptions, and product comments are always extracted in a CDATA block; the rest are placed in an attribute. |
| beCPG.product.report.priceBreaks | extractPriceBreaks | Displays the cost list based on purchase quantities. |
| beCPG.product.report.extractRawMaterial | extractRawMaterial | Extracts raw materials. |
| beCPG.product.report.extractDatalistImage | extractDatalistImage | Extracts image in list |
| beCPG.product.report.multiLevel | extractInMultiLevel | Extracts the composition in multi-level. |
| beCPG.product.report.nonEffectiveComponent | extractNonEffectiveComponent | Extracts non-effective lines in addition to effective lines. |
| beCPG.product.report.maxCompoListLevelToExtract | maxCompoListLevelToExtract | Sets the maximum number of levels to be extracted for the compoList (must be associated with extractInMultiLevel=true). |
| beCPG.product.report.extraImagePaths | extraImagePaths | List of xPaths separated by semicolons allowing indication of images to be extracted. |
| beCPG.product.report.nutList.localesToExtract | nutLocalesToExtract | Extracts rounded nutrient values. |
| beCPG.entity.report.mltext.fields | mlTextFields | Allows extraction of all languages entered in a field. |
| beCPG.entity.report.mltext.locales | mlTextLocales | Specifies the languages to be extracted for mlText fields. |
| beCPG.product.report.showDeprecatedXml | showDeprecatedXml | Displays GDA and nutrients in the old format. |
| beCPG.report.name.format | nameFormat | |
| beCPG.report.title.format | titleFormat | |
| beCPG.report.includeReportInSearch | includeReportInSearch | Displays reports in the search. |
The default values for each parameter are:
| Relative Parameter | Default Value |
|---|---|
| componentDatalistsToExtract | Empty (none) |
| assocsToExtract | bcpg:plants, bcpg:suppliers, bcpg:storageConditionsRef, bcpg:precautionOfUseRef |
| assocsToExtractWithImage | bcpg:clients |
| assocsToExtractWithDataList | |
| assocsToExtractInDataList | |
| entityDatalistsToExtract | Empty (all) |
| multilineProperties | |
| extractPriceBreaks | false |
| extractRawMaterial | false |
| extractDatalistImage | false |
| extractInMultiLevel | false |
| extractNonEffectiveComponent | false |
| maxCompoListLevelToExtract | Empty (no maximum level) |
| extraImagePaths | Empty (none) |
| nutLocalesToExtract | Report locale |
| mlTextFields | |
| mlTextLocales | |
| showDeprecatedXml | false |
| nameFormat | {entity_cm:name} - {report_cm:name} - {locale} - {param1} |
| titleFormat | {report_cm:name} - {locale} - {param1} |
| includeReportInSearch |
Possible customization values are:
| Relative Parameter | Example |
|---|---|
| componentDatalistsToExtract | bcpg:nutList, bcpg:ingLabelingList|bcpg:semiFinishedProduct |
| assocsToExtract | bcpg:trademarkRef |
| assocsToExtractWithImage | bcpg:suppliers, bcpg:clients |
| assocsToExtractWithDataList | bcpg:suppliers, bcpg:clients |
| assocsToExtractInDataList | bcpg:nutListNut |
| entityDatalistsToExtract | bcpg:nutList, bcpg:ingList |
| multilineProperties | cm:title, cm:description |
| extractPriceBreaks | true |
| extractRawMaterial | true |
| extractDatalistImage | true |
| extractInMultiLevel | true |
| extractNonEffectiveComponent | true |
| maxCompoListLevelToExtract | 2 |
| extraImagePaths | cm:Mon_x0020_Dossier//[like(@cm:name, '%PNG', false)];cm:Autre_x0020_Dossier/* |
| nutLocalesToExtract | # - empty: only the report local # - all: all the supportedLocales # - supportedLocale list: en, en_US, en_CA, en_AU, de, es, fr |
| mlTextFields | bcpg:legalName |
| mlTextLocales | fr, en |
| showDeprecatedXml | true |
| nameFormat | {entity_bcpg:erpCode} - {entity_cm:name} - {report_cm:name} - {locale} |
| titleFormat | {entity_bcpg:erpCode} - {report_cm:name} - {locale} - {param1} |
| includeReportInSearch |
Introduction
The extractor enables datasource creation. Since 2.1, beCPG gives the possibility to extract specific aspects of the data by predefined parameters.
The following parameters must be place in [instanceName]/becpg/classes/beCPG.properties.
Parameters with an asterisk, in title, can take several values; values must be separated by a comma ",".
Parameters
becpg.reportServerUrl
This parameter specifies the server on which the BIRT module is located.
Default value:
- becpg.reportServerUrl=http://localhost:8080/becpg-report
beCPG.report.name.format
This parameter specifies to BIRT module, how to named the report.
Default value:
- beCPG.report.name.format={entity_cm:name} - {report_cm:name} - {locale}
beCPG.entity.report.mltext.fields*
Allows to extract all languages entered from a field
Example:
If legal name field (bcpg:legalName) is entered in 2 languages (french & english) and we must display those languages in the report, the following configuration is :
- beCPG.entity.report.mltext.fields=bcpg:legalName
beCPG.product.report.multiLevel
Enables the multi-level extraction. It can take 2 possible values, 'true' and 'false'.
Example:
If this parameter is :
- False : only level 1 elements are extract (see below image, framed in red)
- True : all elements are extracts.
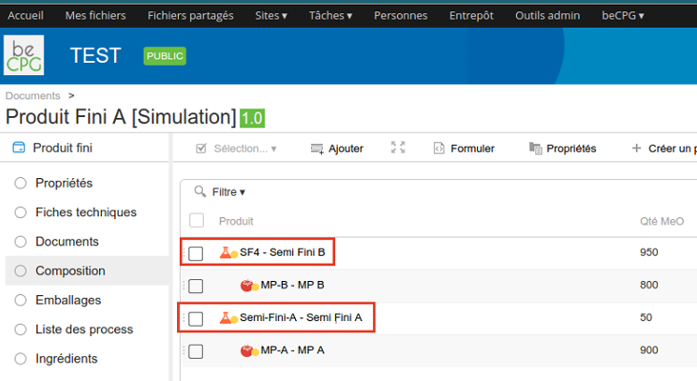
Default value:
- beCPG.product.report.multiLevel=false
beCPG.product.report.nonEffectiveComponent
Allows to include non effective lines in the extraction. It can take 2 possible values, 'true' or 'false'.
Default value:
- beCPG.product.report.nonEffectiveComponent=false
beCPG.product.report.priceBreaks
Allows to display the cost list depending on the purchase amount. it takes 2 possibles values : 'true' and 'false'.
By default, it is equal to 'false'.
beCPG.product.report.assocsToExtract
'Title' and 'Clients' fields, are both Finished Product properties; the first property is a simple property and the second is an associated property (association). By default, only the field 'name' of the associated property is extract by the extractor but sometime, we want to retrieve all data of clients fields (name, address, Phone number, etc). This parameter allows to extract on a product, all properties of an association.
Default value:
- beCPG.product.report.assocsToExtract=bcpg:plants,bcpg:suppliers,bcpg:storageConditionsRef,bcpg:precautionOfUseRef
beCPG.product.report.assocsToExtractWithImage
A finished product has a property 'Clients', which allow to associate a client entity with a product. By default, the extractor doesn't extract images of a associated field while the finished product extraction. This parameter tells the extractor to retrieve entity's images, for example, entity client.
Example: To retrieve client images, pass value bcpg:clients : > beCPG.product.report.assocsToExtractWithImage=bcpg:clients
Default value:
- beCPG.product.report.assocsToExtractWithImage=
beCPG.product.report.assocsToExtractWithDataList
Similar to "beCPG.product.report.assocsToExtract" but allows to extract the dataList of a associated field.
Default value:
- beCPG.product.report.assocsToExtractWithDataList=
beCPG.product.report.componentDatalistsToExtract
A "component" can bea "Raw Material" (RM), a "Simi-finished" (SF), a "Packaging" or a "Packaging Kit".
A product has lists (Composition, Packagings, etc) and contain components into each of them. During a simple extraction, components are extracts without their lists. This parameter allows to extract component's lists.
Example: The following configuration allows to extract the dataList of components from product's composition.
- beCPG.product.report.componentDatalistsToExtract=bcpg:compoListProduct
Default value:
- beCPG.product.report.componentDatalistsToExtract=
Extractor Parameters (Part 2)
Introduction
As seen in the previous part, the extractor setting is in beCPG.properties file and server need to be restarted after each modification.
Since version 2.2.2, it is possible to setup the report extractor directly into beCPG PLM and the server no longer needs to be restarted.
Principles
BeCPG is installed on a system with a default configuration for the extractor. This configuration may be overriden through the new field, Text parameters placed in the properties editing form of report. (see below image)
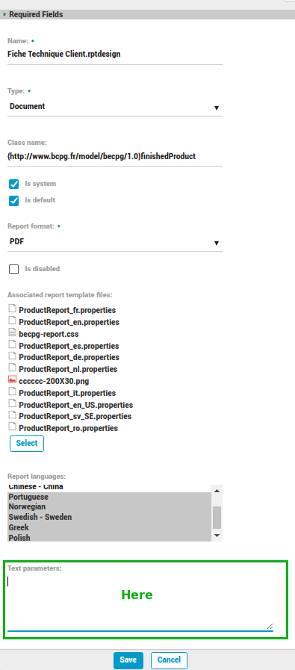
With this override, this is not necessary to reboot the server. The new configuration is take in account for next extractions.
Text parameters contains a JSON object which have keys list.
To begin with, let us list of available keys, then their roles and to finish a pratical use case.
Keys list
- iterationKey
- params
- prefs
- extractInMultiLevel
- extractNonEffectiveComponent
- componentDataListsToExtract
- extractPriceBreaks
- mlTextFields
- assocsToExtract
- assocsToExtractWithDataList
- assocsToExtractWithImage
- nameFormat
- titleFormat
Keys Role
iterationKey : allows to specify on which DataList (Packaging, Composition,...) the extractor must carry out iteration on each component. It is used in conjunction with params keys.
params : is a parameters table. Each parameter object has 2 keys :
- id : is a variable name. The variable name is given arbitrarily to have the possibility to use it with other key, as nameFormat and titleFormat.
** prop : allows to specify the value to retrieve and store it in id** variable.
prefs : is a object and allows to set the extractor behaviour. The parameters taken into account is :
REMARK: click on one of the parameters above to see its role.
nameFormat : allows to codify the PDF report name. By default, the codification is : {entity_cm:name } - {report_cm :name} - {locale} : which gives «Quiche Lorraine – Client specification - fr» for the finished product Quiche Lorraine .
Example : If we want to display the beCPG code of a component of the Composition, nameFormat will have the value: > > > «{entity_cm:name} – {report_cm:name} - {locale} - []{style="param1;"}» > > []{style="param1;"} is a variable which is defined in JSON. We will see how to define it in the use Case section.
titleFormat : allow to codify the report name placed in the reports list. List of generated Reports is in Reports list of an entity.
Use case
Let’s take for exemple, a supplier having multiple plants and you need a report per plant. Each report must contain their name (Production sheet, technical sheet,...) and the plant name.
To do this, you must have created the list Reports beforehand in the supplier model. Once the supplier report created and deployed, you must place in Text parameters field, the following JSON to finish the report configuration:
<code class="json">
{
iterationKey : "bcpg:plant",
params : [{
id: "param1",
prop : "cm:name"
}],
prefs : {
assocsToExtract : "bcpg:plants,bcpg:suppliers,bcpg:storageConditionsRef,bcpg:precautionOfUseRef,bcpg:nutListNut",
assocsToExtractWithDataList : "bcpg:compoListProduct"
},
nameFormat : "{entity_cm:name}- {report_cm:name} - {locale} - {param1} ",
titleFormat : " {report_cm:name} - {locale} - {param1}"
}
</code>
And finally click on 'Create reports' to generate the supplier reports.
Tips
The params table is used with iterationKey. So, it is useless to put one without the other.
If you have overriden a key (mlTextFields, assocsToExtract,…) and you get it out of Text parameters, the Extractor will use the default value.
The defined parameters in JSON params key are extracted in the report dataSource (XML). Example: If params equals to:
<code class="json">
{ ...
params : [{
id: "plantName"
prop: "cm:name"
},
{
id: "plantCertifName"
prop: "bcpg:plantCertifications|cm:name"
}],
...
}
</code>
The XML node corresponding to the result of the JSON parameter will be:
<code class="xml">
<entity> ...
<reportParams>
<plantName nodeRef="workspace://SpacesStore/108624b8-49da-44a0-be1f-7735b7a35143" prop="cm:name" value="Plant XY"/>
<plantCertifName nodeRef="workspace://SpacesStore/108624b8-49da-44a0-be1f-7735b7a35143" prop="bcpg:plantCertifications|cm:name" value="Certification X1"/>
</reportParams>
</entity>
</code>
Notice that :
- the node name is the value specified in id.
- the nodeRef attribute is the current component nodeRef.
- the prop attribute is the text string entered in JSON.
- the value attrtibute is the value stored in "plantName".
- it is possible to retrieve a property of a association using this pattern : "associationKey|attributKey".
There are 2 ways to retrieve a datasource containing the reportParams node. The 1st consists of enabling debug mode in Java. The 2nd way is to consult the rep:reportTextParameters attributes of the generated report node.
We will see the second way, which is easier to do.
After setting up and generating the report: Go to the Documents folder of the entity (Supplier in our example) and click on the pdf report. Get the document (pdf) NodeRef and retrieve the document through the node browser (Read this to know how to retrieve a nodeRef and use the node browser). Once on the document node, look at his rep:reportTextParameters attribute and you will see that it contains a JSON similar to:
<code class="json">
{
"titleFormat":" {report_cm:name} - {nomUsine} - (fr - {locale} )",
"nameFormat":"{entity_cm:name} - {report_cm:name} - {nomUsine} - (fr - {locale} )",
"params":[{
"nodeRef":"workspace://SpacesStore/108624b8-49da-44a0-be1f-7735b7a35143","prop":"cm:name","id":"nomUsine","value":"Usine XY"
},{
"nodeRef":"workspace://SpacesStore/108624b8-49da-44a0-be1f-7735b7a35143","prop":"bcpg:plantCertifications|cm:name","id":"nomCertifUsine","value":"Certification X1"
}],
"prefs":{…} ...
}
</code>
With the matching system, you are able to reconstruct the [reportParams>]{style="text-align:left;"} XML node.
Creating a "Technicals Sheets" list
Introduction
Entities (Finished Product, Raw Material...) have default lists ("Technicals Sheets", "Composition"...). Some entities do not have some lists, for example, "Technicals Sheets" list for the supplier.
Process
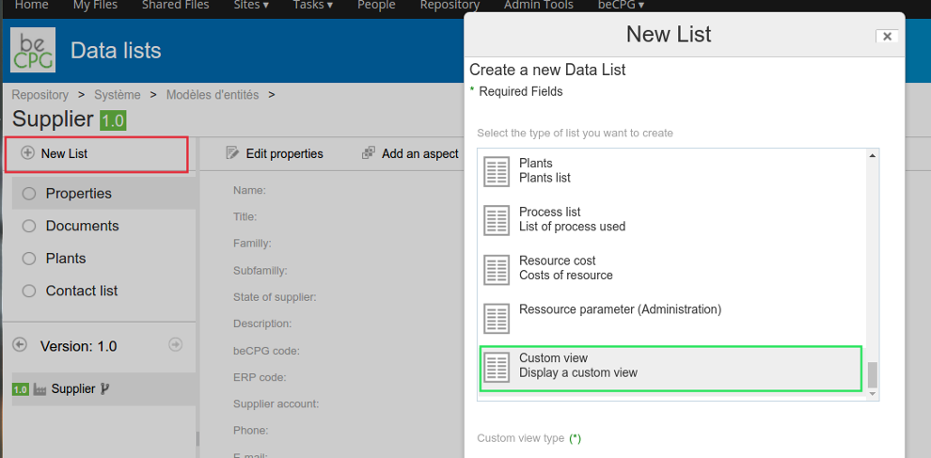
To add a "Technicals Sheets" list on supplier model, you must:
1. Select the "Supplier" model located at "Repository >System > Entities templates" 2. Click on "New list" (see below image, framed in red) then in the Types list, select "Custom view" (see below image, framed in green).
3. Then fill the form fields with the same image indicated on the below image, then save:
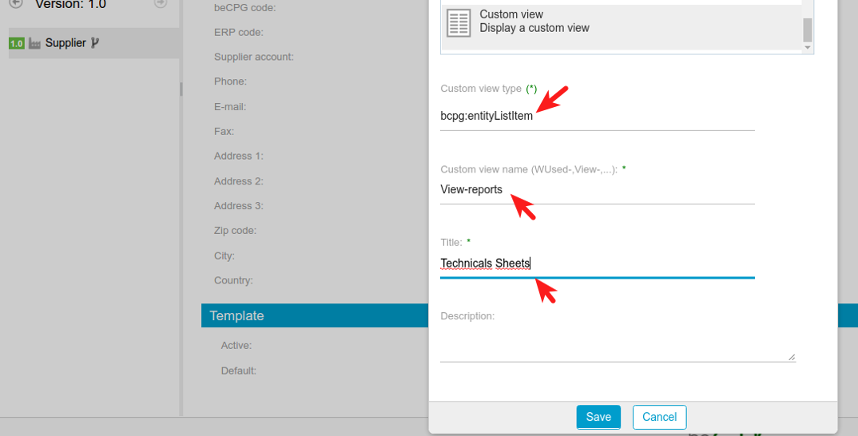
The new Technicals Sheets list is created.
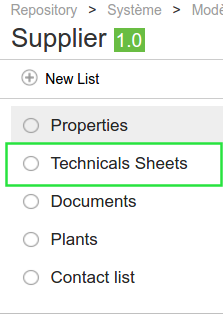{kind=link}
Good Practices - BIRT
In Reports and product sheets section, you get used with Birt Designer. You are well acquainted with Data Explorator tab, Tool Box (contains : tables, text,...) and layout tab (report formatting).
You have probably noticed, there is Outline tab next to Navigator tab. This tab, present the report structure, (cf. below image).
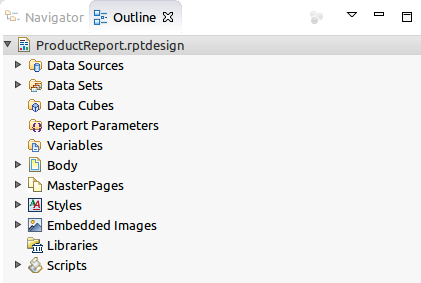
This guide of good practices will deal with some sections present in the structure.
Function declaration
The are instances where a developper creates the same function in different elements (text, data, dynamic text…) in the report. Proceed like this, make the report heavier and when a maintenance is done on this function, you force to modify all elements that contains this function.
In order to optimize the maintenance time, the best way to proceed is to declare the function once and make it available in the whole report. To do this, use ‘Initialize’ event of the report.
Pros:
- Report lighter due to the lack of code duplication.
- Reduce maintenance time.
Use of Aliases
Using an Alias at the fields level of a DataSet is useful when the field key is very different of the name displayed to the user. Use an Alias allow to save time when we must search a field for a specific treatment
Manage images in Birt
In order to minimize report size, make sure that after each report modification all unused integrated images have been deleted.
For efficiency reasons, rename / add / delete an image through the Eclipse Outline tab.
Images must be less than 1 MB in size, and an alert is displayed on the product if they exceed this limit.
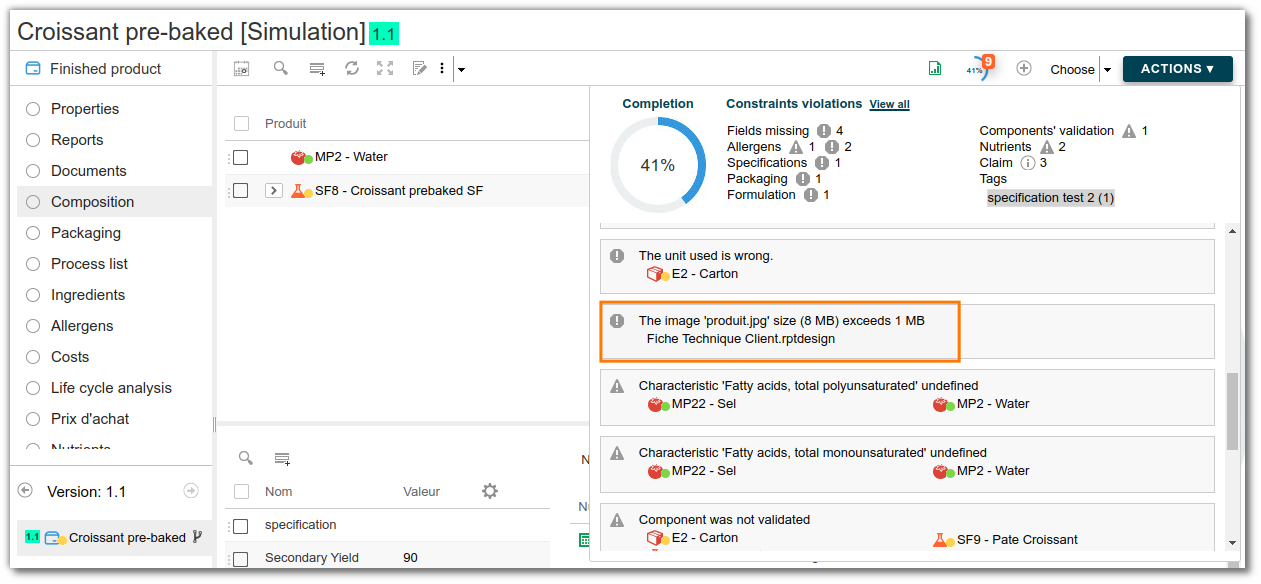
Scripts management (event)
Birt gives the possibility to define JS script at different event levels (Initialize, onPrepare, onRender,...). While an event contains JS code, the event displays in Script section of Outline tab. It is then possible to get a global vision of the whole report elements having a script associated to an event.
Before each delivery, verify that no unused script stays in the report.
To learn more about events and Birt scripts, read this documentation